
Je suis assis avec cette idée de conception d'émetteur depuis un moment, et je ne peux pas me débarrasser de cette idée : “même identifiant, différents émetteurs.” Cela semble propre sur papier… mais quelque chose semble faux.
Regardez, des systèmes comme SIGN traitent les identifiants comme une vérité structurée. Un émetteur définit le schéma, le signe, et boom, quiconque avec les bonnes clés peut le vérifier. Simple. Propre. Lisible par machine.
Donc en théorie, si deux identifiants suivent le même format, ils devraient signifier la même chose.
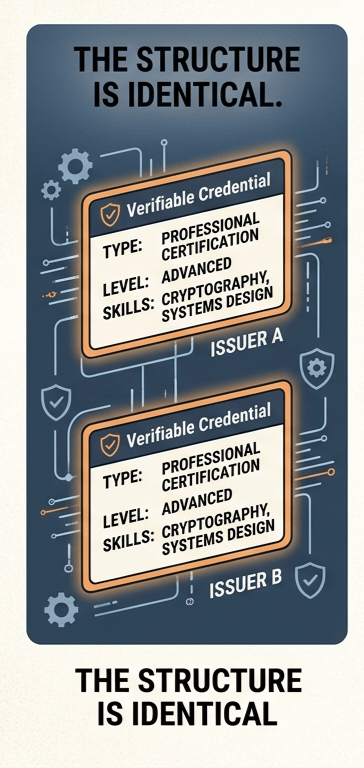
C'est l'hypothèse.
Mais honnêtement ? Cela ne fonctionne que si chaque émetteur pense de la même manière. Et ce n'est pas le cas. Pas même proche.
Prenez quelque chose de basique : une « certification professionnelle ». Ça semble simple, non ?
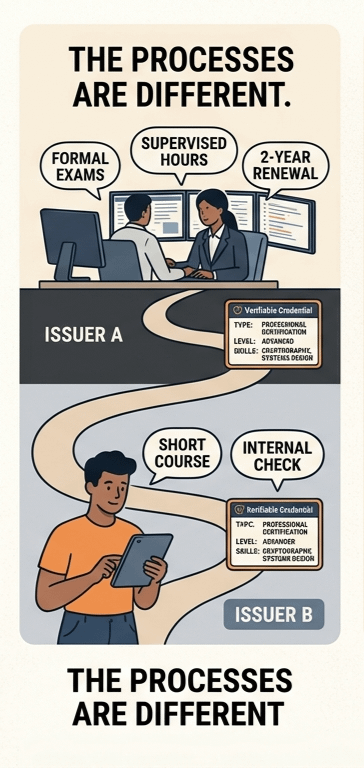
Maintenant, imaginez ceci : un émetteur vous fait passer des examens formels, cumuler des heures supervisées, le renouveler tous les quelques années. Un réel effort.
Un autre émetteur ? Ils le distribuent après un court cours ou un contrôle interne.
Voici la partie folle : les deux identifiants peuvent sembler identiques. Même champs. Même structure. Même validité cryptographique. Tout est en ordre.
Mais ils ne signifient pas la même chose. Pas même à distance.
Et le système ? Il ne le remarquera pas. Il ne peut pas.
D'un point de vue vérification, les deux sont légitimes. Signés. Valides. Terminé.
La différence ne réside pas dans la cryptographie. Elle réside dans les décisions que l'émetteur a prises avant même que l'identifiant n'existe.
C'est à partir de là que les choses commencent à devenir compliquées.
Maintenant, le vérificateur doit réfléchir plus sérieusement. Ce n'est plus juste « est-ce valide ? » maintenant. C'est « d'accord... mais que signifie vraiment cela venant de cet émetteur ? »
Et c'est un problème complètement différent.
Les gens n'en parlent pas assez.
Parce qu'une fois que vous arrivez ici, vous avez essentiellement ajouté une seconde couche d'interprétation au-dessus de la vérification. Et cette couche ? Elle est subjective.
Maintenant, poussez cela à travers les frontières. Différents systèmes. Différentes industries.
Un employeur, un bureau gouvernemental, une plateforme, tous regardent des identifiants qui semblent interchangeables… mais ne le sont pas.
Alors que se passe-t-il ?
Soit vous construisez des normes partagées entre les émetteurs (bonne chance avec ça), soit vous créez une sorte de couche de réputation. Ou et c'est ce qui se passe généralement, vous déchargez le problème sur le vérificateur.
« À grande échelle », disent-ils.
Ouais… ce n'est pas un petit problème.
Parce qu'à présent, la cohérence ne vient plus du système. Elle provient de la coordination. Et la coordination est désordonnée, politique, lente, vous l'appelez comme vous voulez.

Voici la partie qui me marque :
SIGN (ou tout système similaire) peut rendre les identifiants portables. Vérifiable. Facile à transmettre.
Mais la portabilité n'est pas la même chose que l'équivalence. Pas même proche.
Cela signifie juste que vous pouvez vérifier quelque chose. Cela ne signifie pas que cette chose a le même poids partout.
Et c'est là que cela devient intéressant… et un peu inconfortable.
Alors que se passe-t-il à long terme ?
Les systèmes d'identité peuvent-ils rester cohérents lorsque différents émetteurs définissent le « même » identifiant de manières totalement différentes ?
Ou finissons-nous dans un monde où tout vérifie parfaitement…
mais la signification dérive silencieusement au fil du temps ?
Je ne pense pas que nous ayons encore répondu à cela.
