$SIGN #SignDigitalSovereignInfra @SignOfficial

La mayoría de los sistemas en realidad no necesitan saber quién eres.
Simplemente no saben cómo operar sin preguntar.
Esa es la brecha en la que se construye SIGN.
Intentas acceder a algo simple. Una plataforma, un servicio, una función. La decisión en sí es estrecha. Depende de una condición. Pero el sistema no pide esa condición. Te pide a ti.
Identidad completa. Documentos. Detalles que no tienen nada que ver con la decisión que se está tomando.
Al principio se siente como seguridad. Luego comienza a sentirse como hábito.
Realmente no cuestioné las verificaciones de identidad hasta que vi con cuánta frecuencia se utilizan donde no pertenecen.
Al principio se siente normal. Te registras en algún lugar, piden tu identificación, tal vez una selfie, tal vez prueba de dirección. Se ve como cumplimiento. Se ve como protección.
Pero luego miras más de cerca lo que el sistema realmente necesita para decidir.
La mayor parte del tiempo, no está tratando de saber quién eres.
Está tratando de decidir algo mucho más específico.
¿Puedes acceder a este producto? ¿Se te permite en esta región? ¿Cumples con un umbral?
Eso no es identidad.
Eso es elegibilidad.
La parte extraña es cuán raramente los sistemas hacen esa distinción.
Por defecto a la identidad incluso cuando la decisión no depende de ella.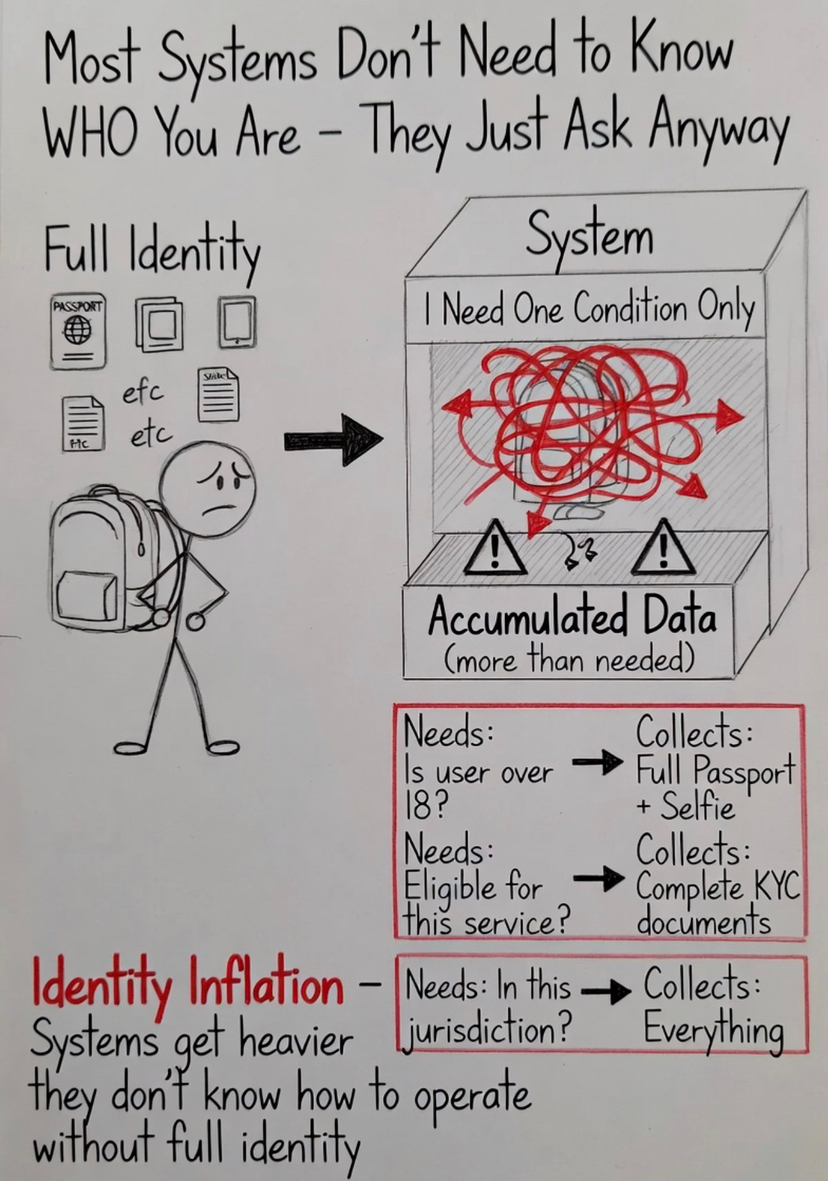
Una plataforma necesita restringir el acceso a adultos. En lugar de verificar la edad, recopila la identidad completa. Un servicio necesita filtrado de jurisdicción. En lugar de verificar el estado de residencia, recopila documentos. Un producto financiero necesita autorización de cumplimiento. En lugar de verificar el estado, reconstruye al usuario desde cero.
Cada vez, el sistema recurre a la identidad porque no tiene una manera de operar sin ella.
La mayoría de los sistemas no recopilan identidad porque la necesitan. La recopilan porque no saben cómo operar sin ella.
Ahí es donde se oculta la ineficiencia.
No en la verificación.
En lo que se verifica.
Porque la identidad es la entrada más pesada posible.
Contiene más información de la que la mayoría de las decisiones requieren. Una vez recopilada, tiende a persistir. Y una vez que persiste, se convierte en parte del sistema ya sea que se necesite o no.
Así que incluso cuando el sistema solo necesita una condición, termina llevando todo.
Por eso la identidad sigue expandiéndose en lugares donde no debería.
Comencé a notar algo más.
Una vez que la identidad entra en el sistema, se vuelve difícil reducirla de nuevo.
El sistema deriva lo que necesita, pero no olvida lo que aprendió.
Así que a lo largo del tiempo, el sistema acumula datos que nunca fueron necesarios para las decisiones que realmente toma.
Eso no es solo ineficiente.
Cambia el perfil de riesgo.
Porque ahora el sistema sostiene más de lo que necesita, procesa más de lo que usa y expone más de lo que debería.
Todo eso, solo para responder una pregunta más pequeña.
Aquí es donde la distinción se vuelve práctica, no teórica.
La prueba de identidad se trata de reconstruir a la persona.
La prueba de elegibilidad se trata de confirmar una condición.
Esos dos flujos no solo difieren en alcance.
Difieren en cómo los sistemas se comportan a su alrededor.
La prueba de identidad jala datos hacia adentro. La prueba de elegibilidad empuja una decisión hacia afuera.
Y ese cambio es donde SIGN deja de ser opcional.
Porque sin una forma de expresar la elegibilidad directamente, los sistemas vuelven a la inflación de identidad.
Lo que cambia con SIGN no es cómo se verifica la identidad.
Es lo que sucede después.
En lugar de tratar la identidad como la entrada para cada decisión, el sistema produce un conjunto de reclamos que reflejan lo que ya se ha establecido.
No todo sobre el usuario.
Solo lo que importa.
Elegible para un servicio específico. Cumple con un nivel de cumplimiento definido. Dentro de un límite de jurisdicción requerido.
Estos no son derivados internamente y mantenidos ocultos.
Se expresan explícitamente, atadas a un esquema y firmadas por el emisor que realizó la verificación.
Así que el significado se mantiene fijo y la fuente de ese significado es clara.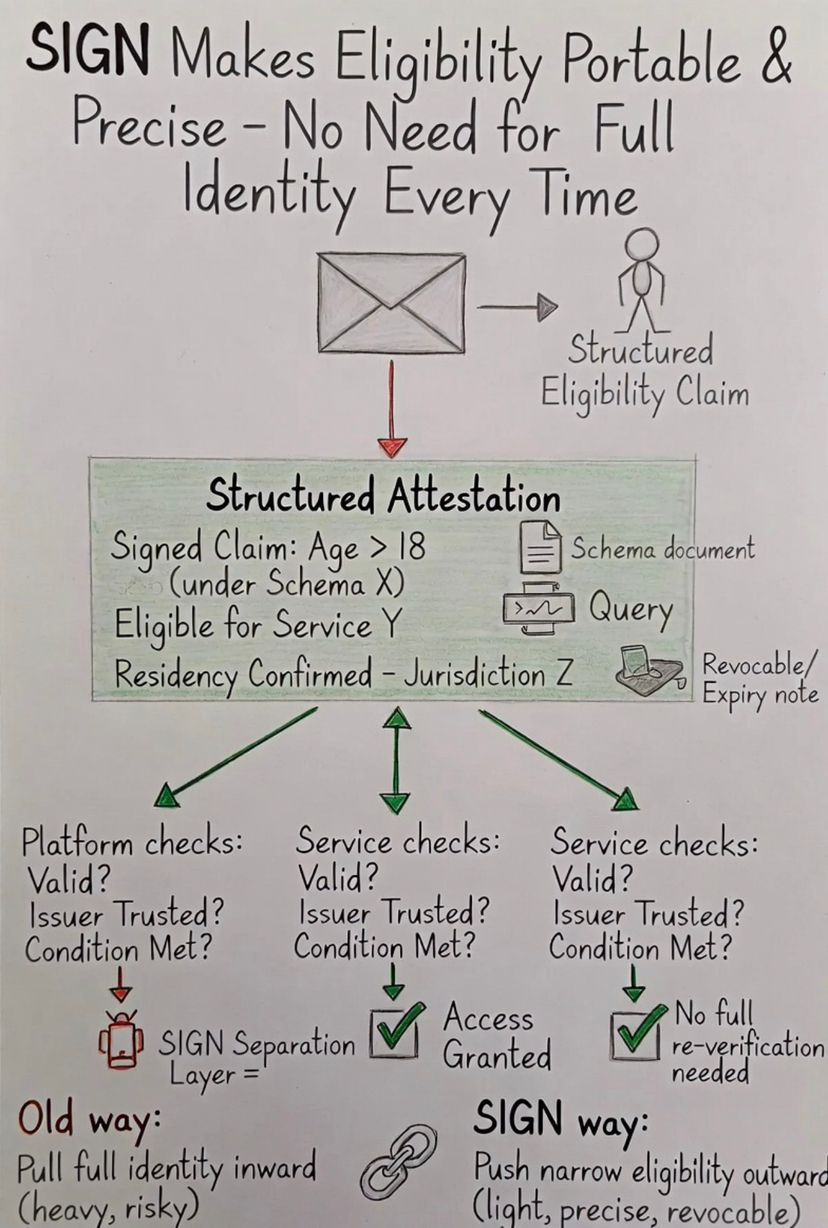
Ahora el siguiente sistema no necesita reconstruir al usuario.
Necesita evaluar el reclamo.
Eso cambia la interacción de una manera sutil pero importante.
El sistema ya no está pidiendo la identidad como entrada cruda.
Está resolviendo si una condición ya ha sido satisfecha bajo reglas que acepta.
Y ahí es donde las cosas se vuelven más precisas.
Porque el sistema solo procesa lo que necesita.
No todo lo que sucede está disponible.
He visto esto suceder en casos donde los sistemas pesados en identidad comienzan a romperse bajo su propio peso.
Los usuarios completan la verificación completa, pero el sistema aún necesita verificaciones adicionales porque no puede aislar la condición exacta de la que depende.
Entonces, en lugar de volverse más simple con el tiempo, se vuelve más complejo.
Más datos, más reglas, más fricción.
El problema no es la falta de información.
Es la falta de separación.
SIGN hace cumplir esa separación al hacer que la elegibilidad sea algo que puede sostenerse por sí misma.
No inferido cada vez, sino emitido una vez y reutilizado donde sea aplicable.
Eso no elimina la confianza del sistema.
Hace que la confianza sea más específica.
Porque ahora cada reclamo está atado a:
un significado definido un emisor responsable de ello y una estructura que no cambia entre sistemas
Así que en lugar de un sistema tratando de entender la lógica interna de otro sistema, dependen de una representación compartida del resultado.
También hay algo más que se vuelve visible cuando lo miras de esta manera.
La elegibilidad no es permanente.
Puede expirar. Puede cambiar. Puede ser revocada.
La identidad no captura eso bien.
Te dice como alguien fue verificado, no si todavía cumple con una condición.
Por eso los sistemas basados en identidad a menudo se desvían.
Verifican correctamente.
Pero no permanecen correctos.
Con la elegibilidad estructurada, ese estado puede ser actualizado.
El reclamo cambia, no todo el proceso de identidad.
Así que el sistema no depende de suposiciones obsoletas.
Resuelve las condiciones actuales.
Aquí es donde las cosas comienzan a sentirse diferentes.
No porque el sistema esté haciendo menos trabajo.
Pero porque está haciendo el trabajo correcto.
En lugar de verificar todo de nuevo, verifica si lo que importa sigue siendo válido.
Y ese es un problema mucho más pequeño.
Una vez que separas la identidad de la elegibilidad, mucha de la presión desaparece.
Los sistemas dejan de recopilar datos innecesarios. Los usuarios dejan de repetir el mismo proceso. Las decisiones se vuelven más claras porque se basan exactamente en lo que requieren.
También cambia cómo los sistemas escalan.
Porque ya no están atados a la reconstrucción de la identidad completa en cada paso.
Operan en condiciones verificadas que pueden moverse a través de fronteras sin expandirse.
Esa es la parte que parece poco discutida.
La mayoría de las mejoras en identidad se centran en hacer la verificación mejor.
Pero el cambio más grande es reducir con qué frecuencia se necesita verificación.
SIGN encaja en ese cambio al hacer la elegibilidad portátil.
No como un efecto secundario, sino como la unidad primaria de interacción.
La identidad aún existe.
Simplemente deja de ser la respuesta predeterminada a cada pregunta.
Y una vez que eso sucede, los sistemas se vuelven más ligeros, más precisos y más fáciles de alinear.
Porque ya no están pidiendo a la persona completa cuando solo necesitan una condición.
Ahí es donde aparece la diferencia.
No en cómo se prueba la identidad.
Pero en lo poco que necesita ser utilizado.
Porque si cada decisión requiere la identidad completa, entonces el sistema no se está volviendo más inteligente.
Simplemente se vuelve más pesado.