I’ll be honest, when I look at Sign Protocol closely, the thing that hits me first isn’t just that it helps people verify information. It’s that it tries to fix the way verification usually works in digital systems. Most systems still verify in a clumsy way. They ask for too much, reveal too much, store too much, and then call that trust. Sign Protocol goes in another direction. It treats trust as something that should be structured, cryptographic, and queryable, but also bounded. That last part matters to me a lot. Because if verification keeps demanding total exposure, then privacy isn’t really protected at all. It’s just delayed until after the damage is already done.
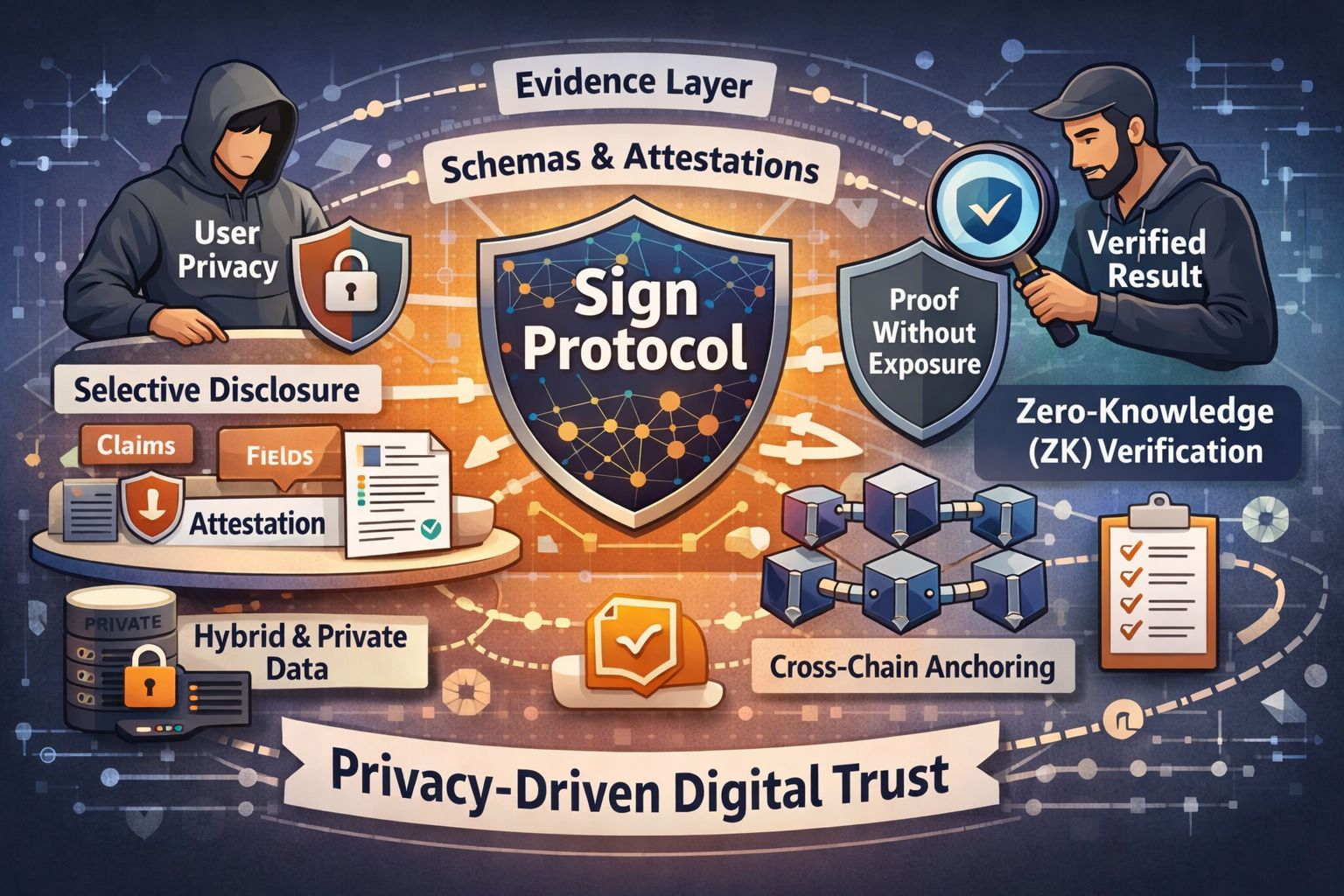
What makes this specifically about SIGN, not just about privacy in general, is the role Sign Protocol plays inside the broader S.I.G.N. architecture. The docs are very clear that Sign Protocol is the evidence layer of the stack. It is the infrastructure used to define structured schemas, issue attestations, anchor evidence across chains and systems, and then query, verify, and audit that data reliably. That means Sign Protocol is not some side tool. It is the layer responsible for how facts are expressed, recorded, proven, and inspected. Once a protocol takes on that role, privacy stops being an accessory. It becomes part of the protocol’s core responsibility.
I think that’s exactly why selective disclosure matters so much here. Sign Protocol is built around schemas and attestations. Schemas define the structure of data: what fields exist, what types they use, how validation works, and how versions are maintained. Attestations are the actual signed statements created under those schemas. That sounds simple on paper, but it has huge consequences. Once data is structured this way, the system can become much more precise about what gets proven and what gets hidden. Instead of treating a credential or record as a giant block that must be shown in full, Sign Protocol makes it possible to think in claims, fields, and proofs. That’s the foundation for selective disclosure.
And to me, that is where the project becomes really sharp. In ordinary digital verification, proving one thing usually means exposing ten others. A user may need to prove they are eligible, authorized, compliant, or approved, but the system often demands a full file, a full document, or a full profile. That is not efficient trust. It is over-collection disguised as verification. Sign Protocol explicitly says it enables selective disclosure and privacy, which tells me the project understands this problem at the architectural level. It is trying to let verification focus on the relevant fact rather than the entire underlying identity or dataset.
I find that especially important because Sign Protocol does not only support one type of attestation. Its own documentation describes attestations as public, private, hybrid, and even ZK-based depending on the use case. That flexibility is not cosmetic. It means the protocol is being designed for environments where not all facts should be treated the same way. Some records may need public visibility. Some may require confidential payloads. Some may need on-chain anchors with off-chain sensitive data. Some may need zero-knowledge properties so the truth can be checked without the underlying secret being revealed. This is a much more mature model than pretending all verified information belongs in one disclosure format.
@SignOfficial That is also why zero-knowledge verification fits SIGN so naturally. I don’t see ZK here as a trendy add-on. I see it as a logical extension of what Sign Protocol is trying to become. If the protocol’s job is to record and verify structured claims across identity systems, payment evidence, compliance flows, public programs, and auditable capital systems, then it has to solve a hard problem: how do you preserve assurance while reducing visibility? Zero-knowledge verification solves exactly that tension. It allows a statement to be proven true without exposing the sensitive data behind the statement itself. In the context of Sign Protocol, that means an attestation can carry strong evidentiary value without forcing the holder to surrender all underlying details every time a check happens.
I think this is where the idea of privacy in SIGN becomes much deeper than simple confidentiality. It is not only about hiding data from the public. It is about controlling how knowledge is distributed across the whole verification process. The docs describe S.I.G.N. systems as being privacy-preserving to the public while still being inspectable by authorized parties and auditable by design. I like that balance. It shows that privacy here is not anti-audit or anti-governance. It is about partitioning visibility properly. The public should not see what it does not need. The verifier should not learn what is irrelevant. But authorized actors can still inspect evidence when their role actually requires it. That is a very different philosophy from blanket transparency.
From my perspective, this is one of the strongest parts of Sign Protocol’s design. It recognizes that trust is not the same thing as exposure. In fact, in many cases, exposure weakens trust because it multiplies risk. The more raw data gets passed around, the more systems must store it, secure it, classify it, govern it, and eventually defend it from misuse. That creates friction everywhere. Developers inherit complexity. Institutions inherit liability. Users inherit vulnerability. When Sign Protocol supports private and hybrid storage models, along with privacy-enhanced modes including ZK attestations where applicable, it is clearly aiming to reduce that burden at the design layer rather than waiting for policy teams to clean it up later.
I also think the schema-driven nature of Sign Protocol makes privacy more actionable. Since schemas define exactly what data is being represented, builders can be deliberate about what belongs inside an attestation and what should remain outside it. That matters a lot. A protocol cannot support meaningful selective disclosure if its underlying data model is sloppy. Structured schemas create discipline. They force precision about fields, field types, and validation rules. And once that precision exists, privacy is no longer vague. It can be engineered into the attestation itself. The proof can be scoped. The disclosure can be narrowed. The audit reference can remain intact even when the sensitive payload is protected.
This is why I’d say privacy in SIGN is not merely a user preference. It is part of the evidence architecture. And that is a crucial difference. If privacy lives only in the interface, it can be bypassed by the structure underneath. But if privacy is built into schemas, storage models, attestation types, and proof mechanisms, then it becomes part of how the system actually thinks. That is what makes Sign Protocol feel robust to me. It is not just asking, “How do we write verifiable data?” It is asking, “How do we write verifiable data in a way that preserves control, reduces oversharing, and still supports querying, auditing, and interoperability?”
I keep coming back to the phrase evidence layer because it explains so much. Evidence is powerful. It affects approvals, compliance, rights, payments, audits, institutional actions, and program eligibility. If the evidence layer is privacy-blind, then the entire system above it becomes dangerous, no matter how elegant the application looks. But if the evidence layer is built with selective disclosure and ZK-aware verification in mind, the whole system becomes more credible. Not just more advanced. More trustworthy. It becomes possible to prove that a condition is satisfied, that a payment was executed, that a rule version applied, or that an entity passed compliance, without normalizing unnecessary revelation in every interaction. That is exactly the sort of controlled verifiability modern infrastructure needs.
And honestly, this is where I think SIGN becomes bigger than a technical protocol conversation. It starts to define a standard for how digital trust should behave. Not loud. Not invasive. Not careless with data. Just precise. Structured. Verifiable. Auditable when required. Private where necessary. That combination is hard to get right, and I think Sign Protocol deserves credit for centering it so explicitly. Its support for schemas, attestations, hybrid data placement, private modes, ZK-based attestations, and immutable audit references all point in the same direction: trust should move, but private data should not spill everywhere just because trust needs to be checked.
So yes, if I were to put it in one clean observation, I’d say this: privacy is central to SIGN’s vision because Sign Protocol is not trying to make people more visible. It is trying to make facts more verifiable. That is a massive difference. Selective disclosure keeps proofs relevant. Zero-knowledge verification keeps assurance strong without forcing exposure. Schemas keep data disciplined. Attestations keep claims portable and machine-readable. Hybrid and private modes keep sensitive information from being carelessly pushed into open contexts. Audit references preserve accountability without collapsing privacy altogether. All of that works together. And when it does, verification stops feeling extractive and starts feeling intelligent. That, to me, is the real promise of $SIGN .