There’s a point in crypto where excitement quietly turns into inefficiency—and for me, on-chain bloat sits right at that edge.
I get the appeal. The idea that we can store data on-chain—immutable, transparent, globally verifiable—still feels powerful. But somewhere along the way, it feels like people stopped asking the obvious question: just because we can store everything on-chain… does that mean we should?
Because the reality is a lot less idealistic.
Putting large amounts of data fully on-chain gets expensive very quickly. Gas fees don’t just creep up—they scale aggressively with how much data you’re pushing. And when you’re dealing with real-world use cases like credentials, attestations, or identity systems, the data isn’t small. It adds up fast. What starts as a clean design turns into something that’s costly, inefficient, and honestly unrealistic to maintain at scale.
This is where my frustration comes in. Blockchain was never meant to be a full storage layer. It’s a verification layer. A coordination layer. Trying to turn it into a data warehouse just doesn’t make sense.
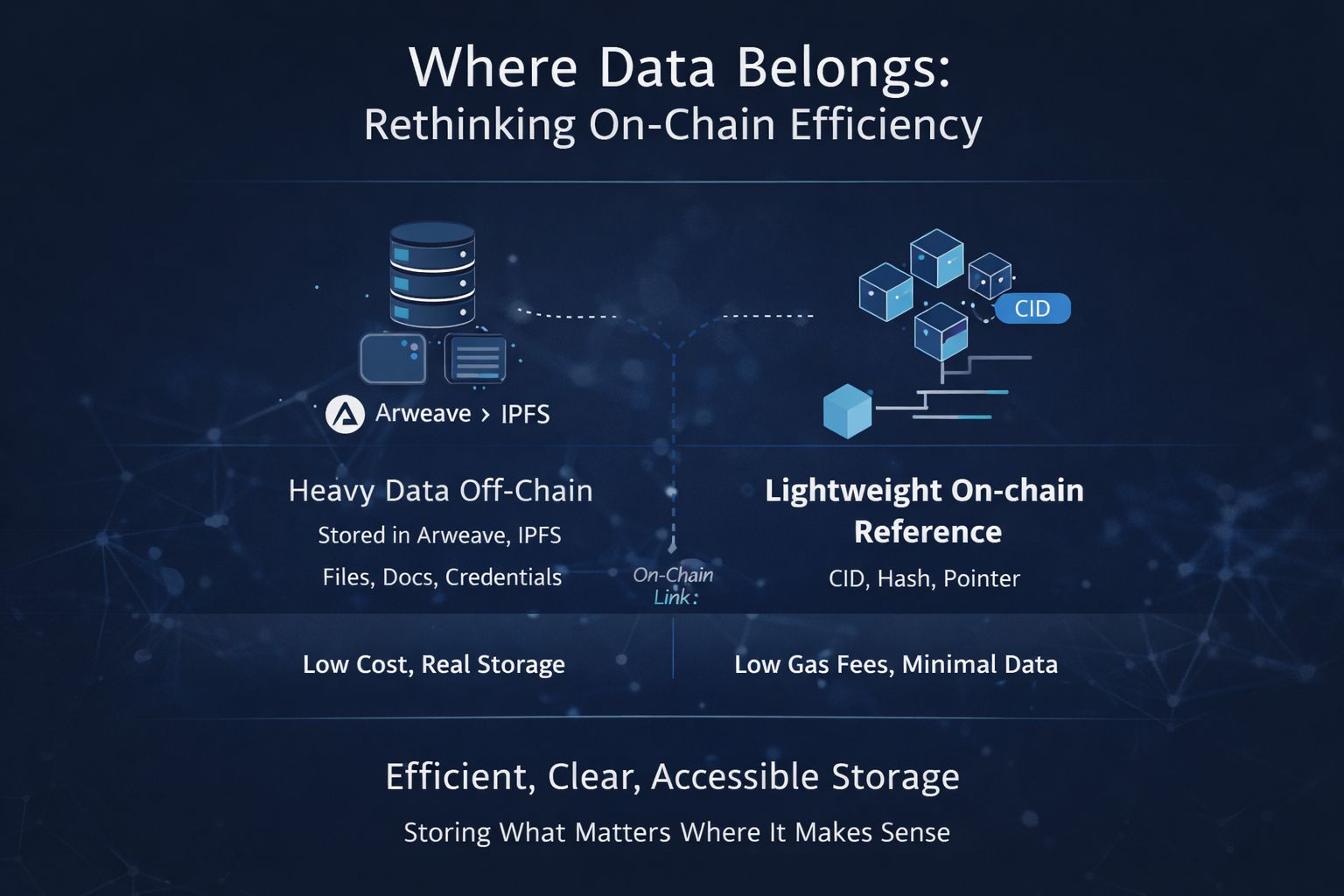
And for bulky data, it becomes obvious: blockchain is often the wrong place.
That’s why the approach behind Sign Protocol actually clicks for me.
Instead of forcing everything on-chain, it takes a more balanced path. Heavy or bulky data is stored off-chain using systems like Arweave or IPFS, while the blockchain only holds a lightweight reference—something like a CID that points to where the real data lives. That alone changes the equation. Costs stay manageable, the chain doesn’t get clogged, and you still retain access to verifiable data.
It’s a simple idea, but it’s surprisingly rare to see it done cleanly.
What I appreciate is that Sign Protocol doesn’t make this confusing. Its schemas and attestations clearly show where the data lives—what’s on-chain, what’s off-chain. There’s no guessing, no hidden assumptions. And that clarity matters more than people think, especially when you’re dealing with real data and real applications. If developers and users can’t easily understand where their data is stored, the system becomes fragile by design.
Another thing that stands out to me is flexibility.
Not everyone wants to rely purely on decentralized storage. In some cases, people need more control. Maybe it’s compliance, maybe it’s internal systems, maybe it’s just preference. Forcing everyone into a single storage model doesn’t work in the real world. And Sign Protocol seems to understand that—it supports custom storage solutions too, which means you’re not locked into one approach.
That kind of optionality is what makes infrastructure actually usable.
At the end of the day, this is what makes sense to me: keep the chain clean. Store only what absolutely needs to be on-chain. Use smarter, more appropriate storage for everything else. Developers should be selective, not excessive. Save gas where it matters. Use the right place for the right kind of data.
 Because efficiency isn’t about doing everything on-chain—it’s about knowing what shouldn’t be there.
Because efficiency isn’t about doing everything on-chain—it’s about knowing what shouldn’t be there.
And that’s exactly why this approach stands out. Sign Protocol feels like it understands the problem at a practical level, not just a conceptual one. It doesn’t try to force an ideal—it works with reality.
@SignOfficial #signdigitalsovereigninfra $SIGN
