
The hidden mess starts after the first payout already looked correct.
A second claim comes in from another wallet. The KYC record looks fine. The address is different. The amount is still inside the program limit. If the system is really only looking at claim surfaces, not the beneficiary underneath them, that second request can look legitimate right up until value leaks twice. That is the kind of failure I kept thinking about while looking through SIGN. It is not flashy. It is just expensive, embarrassing, and very hard to explain later.
What makes SIGN feel more operational than generic distribution tooling is that it keeps tying capital back to identity and evidence. The identity side is built around one citizen and one verifiable identity layer that can work across agencies and regulated operators, while the capital side explicitly calls out identity-linked targeting and duplicate prevention. That is a very different starting point from treating wallets as if they were the person. It means the system is trying to answer a nastier question than "can this address claim?" It is trying to answer "is this actually a distinct beneficiary under the rules of the program?"
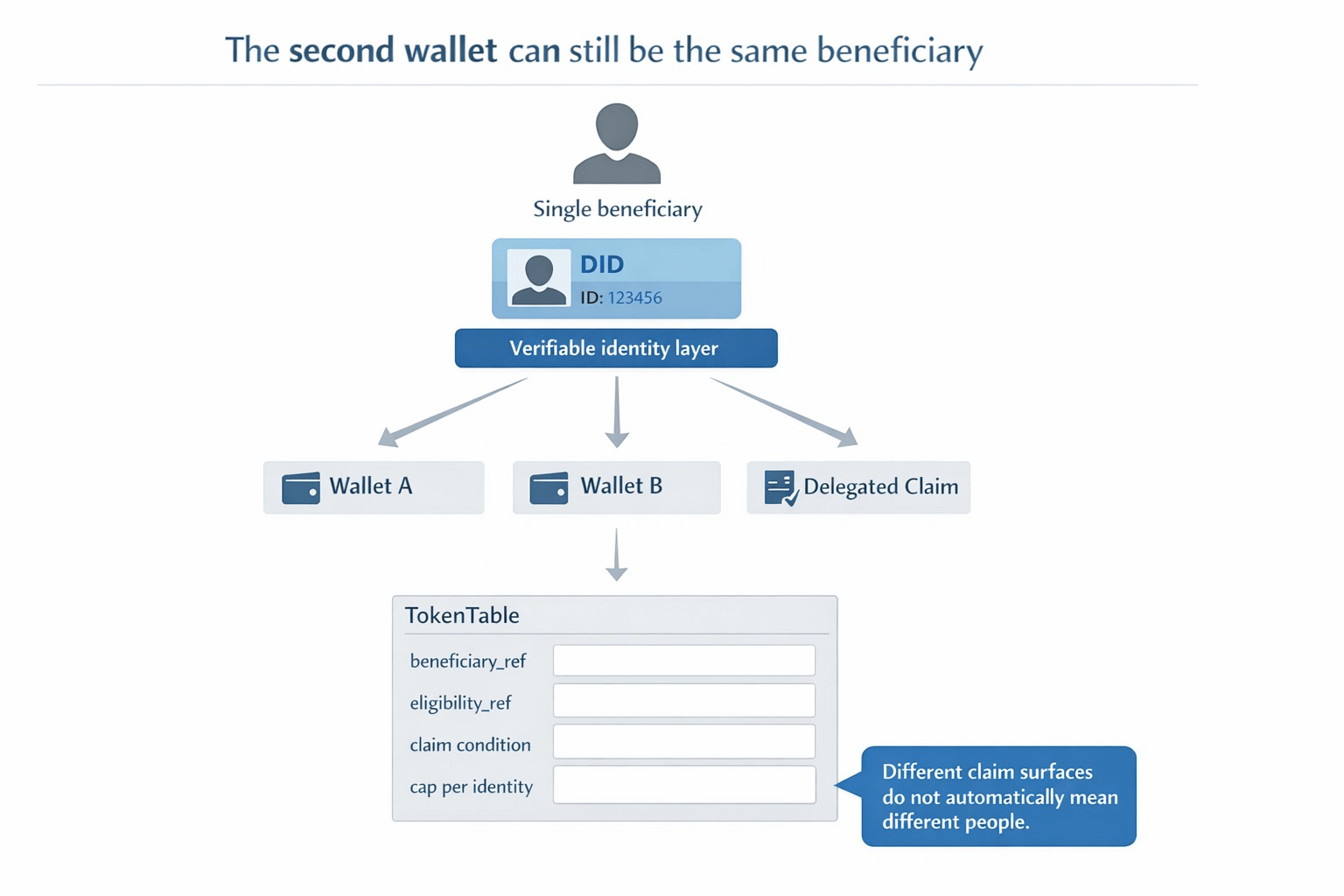
The project-native details are what made this click for me. TokenTable allocation tables are not just lists of addresses and amounts. They can define beneficiary identifiers as DIDs, addresses, or internal references, alongside claim conditions, vesting parameters, and revocation or clawback rules. Those tables are versioned and immutable once finalized. On top of that, eligibility proofs are referenced through attestations, allocation manifests are anchored as evidence, and execution results are linked to settlement attestations so audits can replay the allocation logic later. In other words, the claim is supposed to carry a trail behind it, not just a wallet in front of it.
That creates one very visible consequence for the operator.
The operator should not have to guess whether a new wallet means a new person, a recovery event, a delegated claim path, or someone trying the program twice through another surface. In SIGN's model, the hard controls sit exactly where they should. The capital system calls for hard caps per identity or entity, duplicate prevention via identity linkage, and evidence manifests for audits and disputes. The identity system adds reusable credentials, trust registry checks, and eligibility evidence that can gate capital access. That pushes the workflow away from "this address is not in my spreadsheet yet" and toward "this beneficiary is already represented, already checked, and already accounted for under this ruleset."
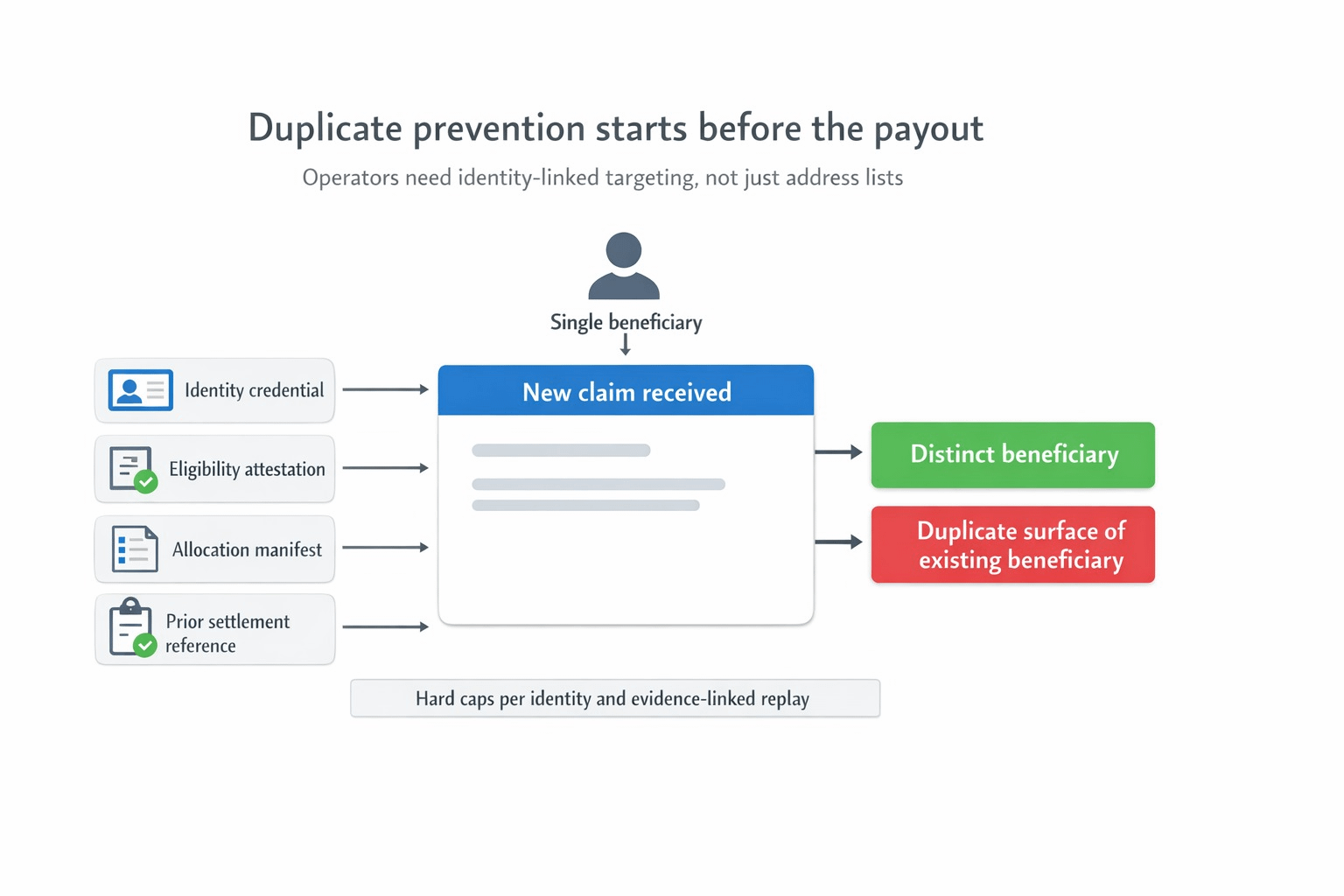
I think that matters more than most distribution teams admit. A lot of programs do not really fail on the happy path. They fail in the overlap between wallet churn, duplicate applications, delegated execution, and partial records across different systems. The second claim is where weak systems suddenly reveal that their idea of identity was never stable enough for money in the first place. SIGN feels sharper here because Sign Protocol is not just storing another proof object. It is acting as the evidence layer for eligibility, allocation, execution, and later audit, while TokenTable keeps the distribution rules deterministic instead of discretionary.
That is why this angle stayed with me. I do not think the real question is whether a program can distribute value at scale. Plenty of systems can do that once. The harder question is whether the system can keep one beneficiary from reappearing as two clean-looking claims without turning the operator back into a spreadsheet detective. If that answer stays weak, then the program is still paying surfaces, not identities.
#SignDigitalSovereignInfra $SIGN @SignOfficial
