There’s a pattern I keep noticing in crypto, especially around attestations and identity systems. Everything sounds ambitious on the surface, but when you look closer, a lot of it leans toward the same mistake: trying to push too much data directly onto the blockchain, as if more on-chain automatically means better.
Honestly, this is where things start to feel frustrating.
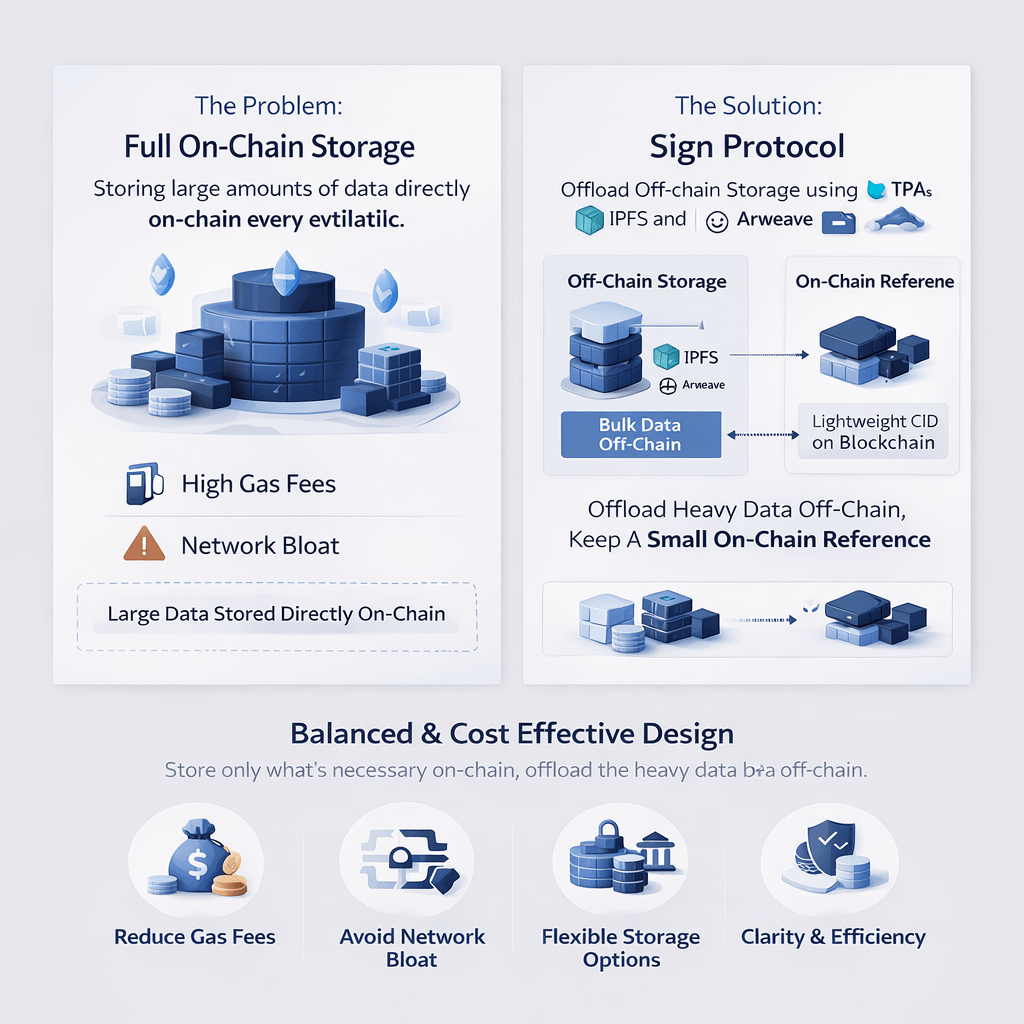
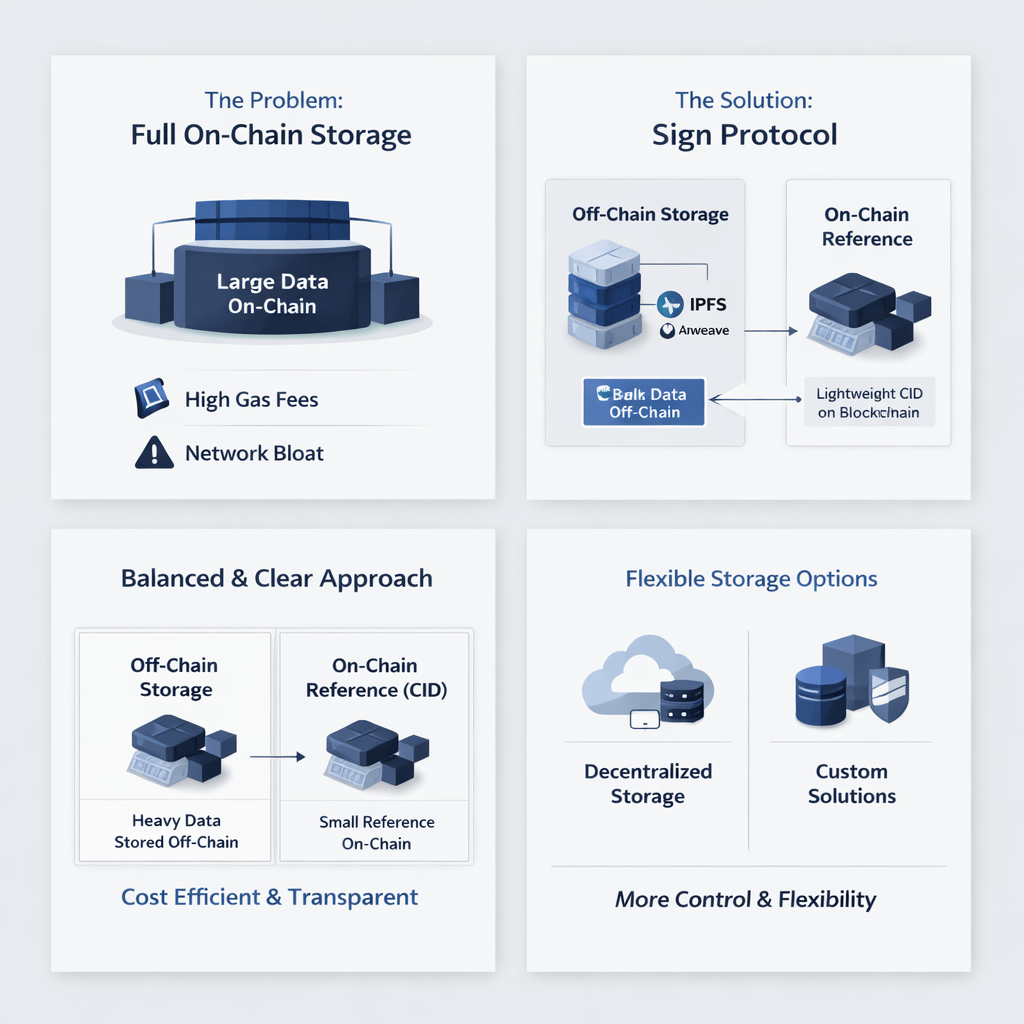 Because putting large amounts of data fully on-chain gets expensive very quickly. Gas fees don’t scale in a friendly way. The more data you store, the more you pay, and not in a small, manageable sense. It becomes unrealistic fast, especially when you move from experiments to real-world use cases like credentials, proofs, or identity records.
Because putting large amounts of data fully on-chain gets expensive very quickly. Gas fees don’t scale in a friendly way. The more data you store, the more you pay, and not in a small, manageable sense. It becomes unrealistic fast, especially when you move from experiments to real-world use cases like credentials, proofs, or identity records.
And for me, this is the core issue: just because blockchain can store something doesn’t mean it should.
For bulky data, blockchain simply isn’t the right place. It was never designed to act as a massive storage layer. It works best as a verification and coordination layer. Trying to force it into being everything at once only creates inefficiency, higher costs, and unnecessary complexity.
This is exactly why the approach behind Sign Protocol makes sense to me.
Instead of pushing all attestation data fully on-chain, it takes a more balanced route. Heavy or bulky data gets stored off-chain using systems like Arweave or IPFS, while the blockchain only holds a lightweight reference, usually something like a CID. That small reference still points to the full data, so nothing is lost, but the chain itself stays clean and efficient.
This approach just feels… practical.
It keeps costs lower, avoids clogging the network, and still preserves access to the real data when you need it. You’re not sacrificing integrity, you’re just being smarter about where things live.
What I also appreciate is how clear the system is. Sign Protocol doesn’t make you guess where your data is stored. Its schemas and attestations are structured in a way that shows exactly what’s on-chain and what’s off-chain. That kind of transparency matters more than people realize, especially when you’re dealing with real data and real applications. Confusion in infrastructure leads to mistakes, and mistakes get expensive.
Another thing that stands out to me is flexibility.
Not everyone is comfortable relying only on decentralized storage like Arweave or IPFS. Some users need more control, or have compliance requirements, or just prefer different setups. Sign Protocol doesn’t force a single path. It supports custom storage solutions too, which means you’re not locked into one system or one philosophy. That freedom is important if this kind of infrastructure is meant to work in the real world, not just in ideal conditions.
At the end of the day, this is what makes sense to me: good infrastructure is balanced. Keep the chain clean. Store only what truly needs to be on-chain. Use smarter, more scalable storage for everything else.
Developers need to be more selective. Save gas where it actually matters. Use the right place for the right kind of data instead of defaulting to “put everything on-chain” just because it sounds more pure.
That’s why this approach clicks for me.
 Sign Protocol feels like it understands the problem at a practical level, not just a theoretical one. It doesn’t try to impress with excess, it focuses on making things work efficiently. And in a space where overengineering is common, that kind of clarity and restraint is exactly what makes it stand out.
Sign Protocol feels like it understands the problem at a practical level, not just a theoretical one. It doesn’t try to impress with excess, it focuses on making things work efficiently. And in a space where overengineering is common, that kind of clarity and restraint is exactly what makes it stand out.
@SignOfficial #signdigitalsovereigninfra $SIGN
